一篇很好的介绍贝叶斯算法的帖子,即使高数考个位数也能看懂(比如我 ^-^)。贝叶斯算法是由英国数学家托马斯·贝叶斯提出的,这个算法的提出是为了解决“逆向概率”的问题。

正向概率:假设一个箱子里有5个黄色球和5个白色球,随机从箱子里拿出一个球,请问取出的是黄球的概率是多少?很容易计算P(黄球)= N(黄球)/N(黄球)+ N(白球) =
5/5+5 = 1/2。
逆向概率:起初我们并不知道箱子里有多少个球,我们依次从箱子里取出10个球,发现这个10个球中有7个白球,3个黄球,那么我们会根据我们观察到的结果去推测箱子里白球与黄球的分布比例大概是7:3,但是我们无法推测出箱子里的球的个数。
贝叶斯算法是一种基于概率统计的机器学习算法,它会计算出每种情况发生的概率,然后对其进行分类,贝叶斯算法经常用于文本分类问题和垃圾邮件过滤问题。假设有一篇新闻报道news report,我们使用贝叶斯算法来判断它们的类别,结果如下:
p(politics|news) = 0.2
p(entertainment|news) = 0.4
p(sports|news) = 0.7
因为p(sports|news)的概率最大,所以我们判断这篇新闻报道为体育类报道。“|”左边为要判断的类别,右边是我们给定的文章。
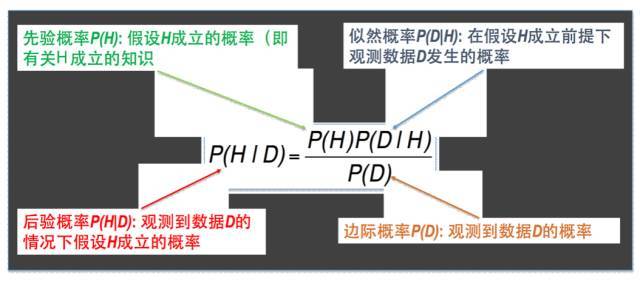
贝叶斯公式推导
接下来,我们将通过一个例子来推导贝叶斯公式。在一所学校里,男生和女生的比例分别是60%和40%,男生全部穿长裤,女生一半穿长裤,一半穿裙子。现迎面走来一个同学,你只能看清他(她)穿的是长裤,而无法分辨出他(她)的性别,请问他(她)是女生的概率?


下面我们逐步计算这个问题:
假设学校里的学生总数为N。
男生人数:N * P(boys),女生人数:N * P(girls)。
穿长裤的男生人数:N * P(boys) * P(pants|boys),其中P(pants|boys)是条件概率的表达形式,意思是男生中穿长裤的概率。因为男生都穿长裤,所以N * P(boys) * P(pants|boys) = 60% * N。
穿长裤的女生的人数:N * P(girs) * P(pants|girls) = 0.2 * N。
穿长裤的总人数:N * P(boys) * P(pants|boys) + N * P(girs) * P(pants|girls)
穿长裤的同学是女生的概率:P(girl|pants) = N * P(girs) * P(pants|girls) / N * P(boys) * P(pants|boy
s) + N * P(girs) * P(pants|girls) = P(girs)*P(pants|girls) / P(pants),分母用P(pants)表示穿长裤的概率。
最终结果:P(girl | pants) = P(pants | girl) * P(girl) / P(pants)
其中:P(girl)我们称为先验概率,是已知值,在这个例子中P(girl) = 40%。先验概率:根据以往的经验和分析得到的结果,先验概率和其他条件的影响不受样本影响。
P(girl | pants)我们称为后验概率,根据观察到的结果,去反推是女生的概率。
换一种更直白的表述:假设学校里面人的总数是 U 个。60% 的男生都穿长裤,于是我们得到了 U * P(Boy) * P(Pants|Boy) 个穿长裤的(男生)(其中 P(Boy) 是男生的概率 = 60%,这里可以简单的理解为男生的比例;P(Pants|Boy) 是条件概率,即在 Boy 这个条件下穿长裤的概率是多大,这里是 100% ,因为所有男生都穿长裤)。40% 的女生里面又有一半(50%)是穿长裤的,于是我们又得到了 U * P(Girl) * P(Pants|Girl) 个穿长裤的(女生)。加起来一共是 U * P(Boy) * P(Pants|Boy) + U * P(Girl) * P(Pants|Girl) 个穿长裤的,其中有 U * P(Girl) * P(Pants|Girl) 个女生。两者一比就是你要求的答案。
下面我们把这个答案形式化一下:我们要求的是 P(Girl|Pants) (穿长裤的人里面有多少女生),我们计算的结果是 U * P(Girl) * P(Pants|Girl) / [U * P(Boy) * P(Pants|Boy) + U * P(Girl) * P(Pants|Girl)] 。容易发现这里校园内人的总数是无关的,可以消去。于是得到
P(Girl|Pants) = P(Girl) * P(Pants|Girl) / [P(Boy) * P(Pants|Boy) + P(Girl) * P(Pants|Girl)]
注意,如果把上式收缩起来,分母其实就是 P(Pants) ,分子其实就是 P(Pants, Girl) 。而这个比例很自然地就读作:在穿长裤的人( P(Pants) )里面有多少(穿长裤)的女孩( P(Pants, Girl) )。
上式中的 Pants 和 Boy/Girl 可以指代一切东西,所以其一般形式就是:
P(B|A) = P(A|B) * P(B) / [P(A|B) * P(B) + P(A|~B) * P(~B) ]
收缩起来就是:
P(B|A) = P(AB) / P(A)
其实这个就等于:
P(B|A) * P(A) = P(AB)
难怪拉普拉斯说概率论只是把常识用数学公式表达了出来。
贝叶斯数学表达式
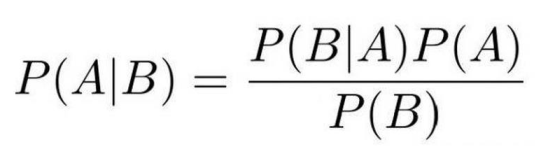

贝叶斯算法在垃圾邮件过滤中的应用
给定一封邮件,判定它是否属于垃圾邮件?用D 来表示这封邮件,注意D 由N 个单词组成。我们用h+ 来表示垃圾邮件,h-表示正常邮件。
有贝叶斯公式可得:
P(h+ | D) = P(D | h+) * P(h+) / P(D)
P(h- | D) = P(D | h-) * P(h-) / P(D)
其中P(h+),P(h-)为先验概率,假如我们有1000封邮件,其中有50封是垃圾邮件,其他都是正常邮件,那么P(h+),P(h-)的概率就是已知的。两个式子的分母都是P(D),所以P(D)对于最终结果的比较是没有影响的。接下来就是要求P(D | h+),P(D | h-)垃圾邮件中或正常邮件中是邮件D的概率。
我们都知道一封邮件是由许多词构成的,所以我们将P(D | h+)的表达式转化为P(d1,d2,d3……dn | h+),就是看垃圾邮件中出现d1,d2…dn这些词的概率是多少。
P(d1,d2,d3……dn | h+) = P(d1 | h+) * P(d2 |d1,h+) * P(d3 |d1,d2,h+) …
这个式子计算起来非常困难,所以在这里我们做一个假设,假设每个词都是独立的并且互不影响,那么这个式子就可以表示为:
P(d1,d2,d3……dn | h+) = P(d1 | h+) * P(d2 | h+) * P(d3 | h+) …P(dn | h+)
P(h+ | D) = {P(d1 | h+) * P(d2 | h+) * P(d3 | h+) …P(dn | h+)}* P(h+) / P(D)
上述这个式子我们就称为朴素贝叶斯公式,朴素贝叶斯公式是对贝叶斯公式的简化,它建立在每个条子互相独立的基础上。
在现实生活中,我们写的每一句话中词与词之间肯定是有相互联系,如果没有联系,那么这句话是读不通的。那么为什么朴素贝叶斯能够在计算中使用,首先是计算简单,其次对最终结果的影响非常小。
参考资料
1.唐宇迪,《机器学习与数据分析实战》课程。
2.Peter,《机器学习实战》。


