文章是2014年的,据作者原文说,当时是 单mongod测试(即只有一个mongod程序实例),测试机均为4g内存双核cpu(64位系统),测试所用文档为简单的三个字段的文档:。以下数据只是证明一个问题,update会很慢 🙂
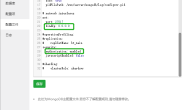
测试所用文档为:
DBObject doc = newBasicDBObject();
doc.put("test","test"+insertNum);
doc.put("no", insertNum);
doc.put("time",swapWords(sld.format(new Date())));
一、入库效率:
1、普通集合入库,
- 每10万条数据平均2~3秒
- 入库一亿条数据大概45分钟
2、四个索引的普通集合
- 初始每10万条5~6秒,时间逐渐增长,到千万级别时每10万条入库时间60~80秒
- 入库一千万数据一小时多一点
3、一个索引的普通集合
- 初始入库每10万条3秒左右,耗时逐渐增长,到四千万左右时每10万条入库时间15~20秒
- 入库一千万数据7、8分钟
- 入库四千万数据大概一个半小时
4、固定集合
- 初始入库每10万条数据平均2~2.5秒
5、一个索引的固定集合
- 初始入库每10万条数据平均3~4秒
二、查询效率:
- 没有索引会进行表扫描(大表会极慢)
- 无论有没有索引,大批量插入时查询效率极慢
三、插入时机器负载:
- 没索引时:cpu不到20%
- 有索引时,初始插入cpu 20,30~40,后期比较慢不到5~15% 猜测原因内存已经用满,磁盘io比较多
mongos测试(三台机器的简单无备份mongod分片群)
一、简单入库
- test集合,分片,无索引,文档结构大小同上例
- 每10万条记录 3~3.5秒
从sqlserver测试表导数据至mongos(三台)测试
一、第一种入库策略:
- 先入库,再建索引及分片,按索引分片
- 1、测试表Test共20列1.5亿数据
- 2、导到mongos时表不设索引,不分片,等到入库完毕后再进行这些操作
- 3、导出时所有列都用的string
- 4、1亿5千万入库6个半小时 10万/10~20秒(从远程的sqlserver数据库导入,一边遍历结果集一边插入,所以实际入库速度应该比这个快)
- 5、建userid,city的二级索引大概用了半个小时(从日志中查看)
- 6、按索引中(userid,city)的一个键分片(而不是用objectid);
- 操作是阻塞式的,吃完饭回来就完成了。。应该是在一个半小时内
- 7、在有分片及索引的情况下,追加插入效率较差,每1000条 20~30秒
- 8、所以考虑:撤销索引,查看集合行数(看是否有影响),追加插入数据,建立索引,测试查询。但是刚刚撤销索集群就无法访问了(因为分片是按索引userid分的).
二、查询:
- 建立索引后:
- 几次测试,同一个程序10000条数据连续查询,平均11~13毫秒
- 并发测试,3个程序同时分别连续查询10000条数据,平均14毫秒
三、删除集合不会释放硬盘空间
- 1、删除后的表不会释放硬盘空间而是内部标记为空闲,需要注意
- 2、可以用db.repairDatabase()整理磁盘文件:
- mongos会分mongod分别处理,每个mongod处理自己的
- 程序首先会将所有有效数据写入临时文件(在他的文件系统中发现诸如_tmp等文件中数据文件增加很多,而且其中文件格式和源数据文件格式相似),所以硬盘占用率会很明显的上升,完成整理后硬盘占用减少。
3、所以如果使用此方法:
- 应该保证磁盘剩余空间容量>mongodb数据文件中有效数据量,
- 保险方法是磁盘剩余空间>mongodb数据文件
4、时间
- 比较慢,不到180g有效数据分在三台机器,用了1~3个小时
4、在此过程中查询:
- 在此过程中读写几乎不能用
四、第二种入库策略:
- 按objectid分片,索引及入库策略不变
- 1、 初始入库时间大致和之前相同(1.5亿条数据)
- 2、 追加存入重复数据
- 20万条10分钟(先遍历sqlserver结果集存入内存中再一次性入库mongodb)
- 3、 追加新数据入库
- 20万条2分半钟(先遍历sqlserver结果集存入内存中再一次性入库mongodb)
- 4、 根据非objectid键更新插入(upsert)
- 很慢,1000条需要6~8分钟(实际上操作失败,因为upsert操作需要指定分片键objectid)
5、 查询
- 速度比之前方案稍慢,35~40毫秒平均(连续查询20000次)
其他
- 1、 windows,linux混合集群测试
- 可行,效率没大规模用过,不知道是否稳定。Linux方面程序不会主动释放内存,windows程序据观察在入库时内存占用量增大,但是入库完后会释放。
- 2、 32位windows系统程序确实只能存2g数据,大于2g数据后程序报错退出。
如需转载请注明: 转载自26点的博客
本文链接地址: mongodb增删改查操作效率一览
转载请注明:26点的博客 » mongodb增删改查操作效率一览